
| Zgłaszanie | Wszystkie zgłoszenia | Najlepsze | Lista |
PYJPG - Python: JPEG |

Witajcie! Jest to kolejny z serii tutoriali uczący Pythona, a w przyszłości być może nawet Cythona i Numby. Jeśli chcesz nauczyć się nowych, zaawansowanych konstrukcji Pythona to spróbuj rozwiązać kilka następnych zadań. Powodzenia!

Kompresja obrazu JPEG jest istotną technologią, która zmieniła oblicze internetu. Technologia ta głównie eksploatuje fakt że ludzie gorzej rozpoznają zmiany w odcieniu niż w jasności pikseli oraz fakt że ludzie gorzej rozpoznają zmiany w obrazie o wysokiej częstotliwości niż w obrazie przypominającym jednolity kolor. W tym zadaniu zaimplementujemy kompresję JPEG, nie będącą kalką ze standardu ale własną metodę opartą na tych samych narzędziach.
Zakładam że umiesz już posługiwać się tablicami w numpy'u. Jeśli nie, lepiej powróć do poprzednich zadań. W tym zadaniu będziesz potrzebował wielu z metod numpy'a. Wszystkie funkcje są dostępne w dokumentacji w zakładce Routines.
Zadanie
1. Wczytanie obrazka
Obraz jest reprezentowany przez 3-wymiarową tablicę liczb w zakresie 0..255. Pierwszy wymiar odnosi się do wysokości obrazka, drugi wymiar do szerokości obrazka, trzeci wymiar do komponentów RGB.
Na wejściu znajduje się zawartość pliku NPY. Do wczytania tablicy powinieneś użyć poniższego kodu:
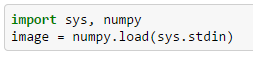
2. Przestrzeń kolorów
Warstwy RGB trzeba zamienić na warstwy chrominancji i luminancji, YCbCr. Konwersja jest bezpośrednia, należy użyć poniższych zależności. Wartości nie są zaokrąglane a dalsze etapy (mimo mylącego wyglądu przykładów) są prowadzone na liczbach rzeczywistych:

3. Zmniejszenie rozdzielczości
Warstwy Cb i Cr są skalowane do połowy rozdzielczości. Każda grupa 2x2 piksele jest zastępowana średnią z owych 4 pikseli. Jeśli brakuje parzystej kolumny, ostatnia kolumna jest duplikowana. Jeśli brakuje parzystego wiersza, ostatni wiersz jest duplikowany. Dla przykładu:
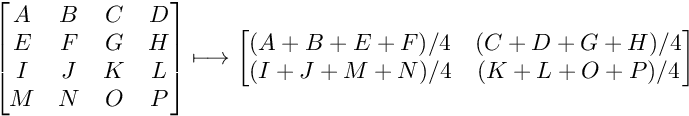
4. Podział na bloki
Każdą z trzech warstw należy podzielić na bloki 8x8 pikseli. Warstwy chrominancji muszą być już pomniejszone przed tym etapem. Bloki na krawędziach, jeśli brakuje pikseli do wypełnienia bloku, duplikują ostatnią kolumnę oraz ostatni wiersz. Dla przykładu:
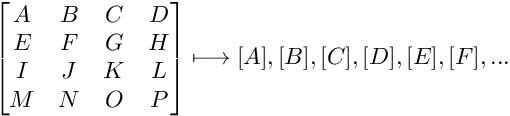
5. Dyskretna transformacja kosinusów
Dla każdego bloku 8x8 pikseli należy obliczyć współczynniki DCT. Współczynniki także tworzą tablicę 8x8 wartości. Trudność polega na tym, że trzeba stablicować jak największą część obliczeń by przetwarzanie każdego bloku było jak najszybsze. Poniżej przykład (wartości zaokrąglone):
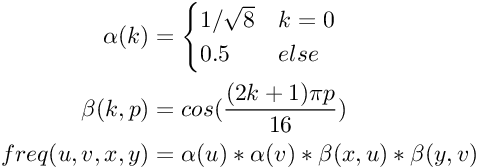
6. Kwantyzacja
Każdy ze współczynników DCT trzeba podzielić przez odpowiedni dzielnik i zaokrąglić. Po tym etapie blok składa się z całkowitych liczb, choć mogą być one ujemne i nie mają ustalonego zakresu.

7. Kodowanie ciągów powtórzeń
Podzielone współczynniki są bardzo często zerami. Najpierw zmienimy kolejność wartości z od-góry-od-lewej na zigzag. Poniżej znajduje się mapowanie indeksów:

Następnie kodujemy 64 wartości, w podanej powyżej kolejności, na ciąg krotek, gdzie krotka zawiera dwa pola (Z,X). Z oznacza maksymalną ilość zer poprzedzającą liczbę X. Ponadto Z może wynieść maksymalnie 15, co powoduje że dłuższe ciągi zer trzeba reprezentować więcej niż jedną krotką. Ilość krotek zależy od tablicy, ale krotki muszą wyczerpać wszystkie 64 elementy. Poniższy przykład powinien wyjaśnić wszystko:

8. Kodowanie entropii
Zbieramy wszystkie krotki (Z,X) do jednej dużej listy (kolejno, dla warstw w kolejności Y Cb Cr, dla bloków od góry, od lewej). Zliczamy ilość wystąpień każdego typu krotki. Posiadając zliczone ilości, zbudujemy listę węzłów które będziemy grupować do postaci drzewa. Początkowe węzły reprezentują każdy typ krotki (Z,X) wraz z licznością C, w kolejności wyznaczonej przez listę krotek.
W pętli, dopóki mamy więcej niż 1 węzeł, wybieramy najwcześniejszy węzeł o najmniejszej liczności (L) i usuwamy go z listy węzłów. Następnie wybieramy najwcześniejszy węzeł o najmniejszej liczności (R) i usuwamy go z listy węzłów. Następnie wstawiamy na koniec listy węzłów nowy węzeł, zawierający sumę liczności L i R, lewą gałąź L, prawą gałąź R.
Ostatni węzeł "na wierzchu" stanowi korzeń drzewa. Wszystkie węzły drzewa poza liściami oznaczają rozdroża, dodając bit 0 do węzłów idących w lewo, i dodając bit 1 do węzłów idących w prawo. Kod krotki (Z,X) stanowi ciąg bitów jakie odwiedzamy ścieżką od korzenia do liścia. Przykład jest kontynuowany poniżej:

Powracając do listy 2-krotek z początku etapu, zastępujemy każdą krotkę ciągiem bitów, kodem zmiennej długości. Jeśli całkowita ilość bitów nie jest wielokrotnością 8, dopisujemy na końcu zera. Kontynuacja przykładu:

9. Zapisanie ciągu bitów
Ostateczny ciąg bitów należy wypisać na standardowe wyjście w postaci binarnej. Kontynuacja przykładu:

Do wypisania bajtów możesz użyć kodu poniżej:

Format I/O
Dane wejściowe stanowi zawartość pliku o formacie NPY. Numpy używa tego formatu do zapisywania pojedyńczych tablic. Wymiary tablicy i typ danych dtype są zawarte w formacie. Obiekt tablicy udostępnia wszystkie wymiary.
Dane wyjściowe stanowi ciąg bajtów w binarnej formie.
Przykładowe dane (niedostępne) można pobrać stąd. Do wczytania użyj kodu:

| Dodane przez: | Arkadiusz Bulski |
| Data dodania: | 2015-01-18 |
| Limit czasu wykonania programu: | 1s-4s |
| Limit długości kodu źródłowego | 50000B |
| Limit pamięci: | 1536MB |
| Cluster: | Cube (Intel G860) |
| Języki programowania: | PYTHON PYPY PYTHON3 |
| Pochodzenie: | :) |